
Monotonic Stack 101
Another post, another coding challenge.
The problem is simple:
Given an array of integers, return an array such that
solution[i]is the number of positions until a positionjwherevalues[j] > values[i]. If there is nojsuch thatvalues[j] > values[i], thensolution[i] == 0.
What!? It’s much simpler than that. This is known as the daily temperatures problem in LeetCode.
Let’s start with a naive solution and see later how can we do better!
Naive solution
The simplest (and most inefficient in this case) thing that we can do, is to just check for every single element i in the given array,
if there is an element with index j such that j > i and values[j] > values[i]. If we found such element, then the solution for i
is the distance between j and i which is j - i.
If we cannot find such element, then we don’t need to do anything as int[] in Java are intialized with a 0 in each position.
public int[] dailyTemperatures(int[] values) {
int[] solution = new int[values.length];
for (int i = 0; i < values.length ; i++) {
for (int j = i + 1; j < values.length; j++) {
if (values[j] > values[i]) {
solution[i] = j - i;
break;
}
}
}
return solution;
}As you might imagine, the time complexity of this solution is O(n^2). This is because for each element, we need to potentially inspect all elements
ahead. So for i = 0 we inspect n elements. For i = 1 we inspect n - 1.
The recurrence relation for this process is:
Because solving the problem T(N) involves a linear scan and then solving the same problem for one less element.
Using a monotonic stack
Now we get into the juicy part. Can we do better than that? Yes we can but it’s not going to be that simple.
We would like to solve this problem in the fastest way we can, which would be linear time as we need to provide an answer for every single element of the input, an array of size N.
Every time we process an element, the answer to the question “How far away is the next element greater than this one?” cannot be solved yet, as we haven’t processed those elements that lie ahead in the array. So what we are going to do is to store those elements in a stack so they can be processed later on.
The algorithm has 2 parts:
- Add current element to a stack so we can process it later.
- Check if the current element can be used to solve some of the previous unsolved items.
If at the top of the stack there is an element smaller than the current element, then the distance between the top of the stack and the current element is the answer. Now that we know the answer, we can remove that element from our “pending to be processed” stack.
Let’s go through an example before jumping into the code:
- Our input array is
[4,3,1,6,5,7] - We construct a new array with the same size as the input to store our results
int[] result = new int[values.length];. - We declare a
new Stack<>()that will help us processing the elements. -
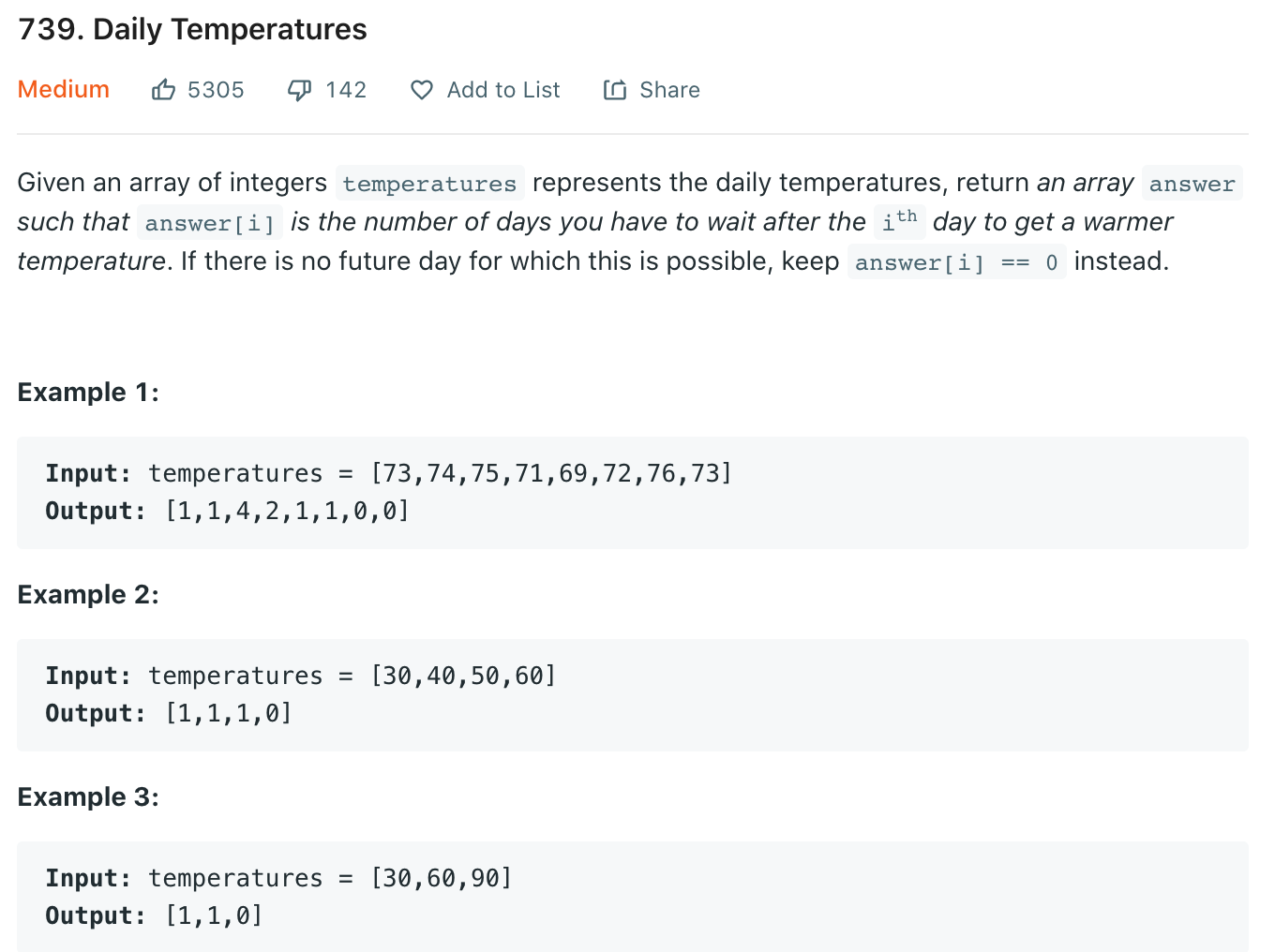
We process element index
0and value4, and because the stack is empty we just put it in the stack to be processed later.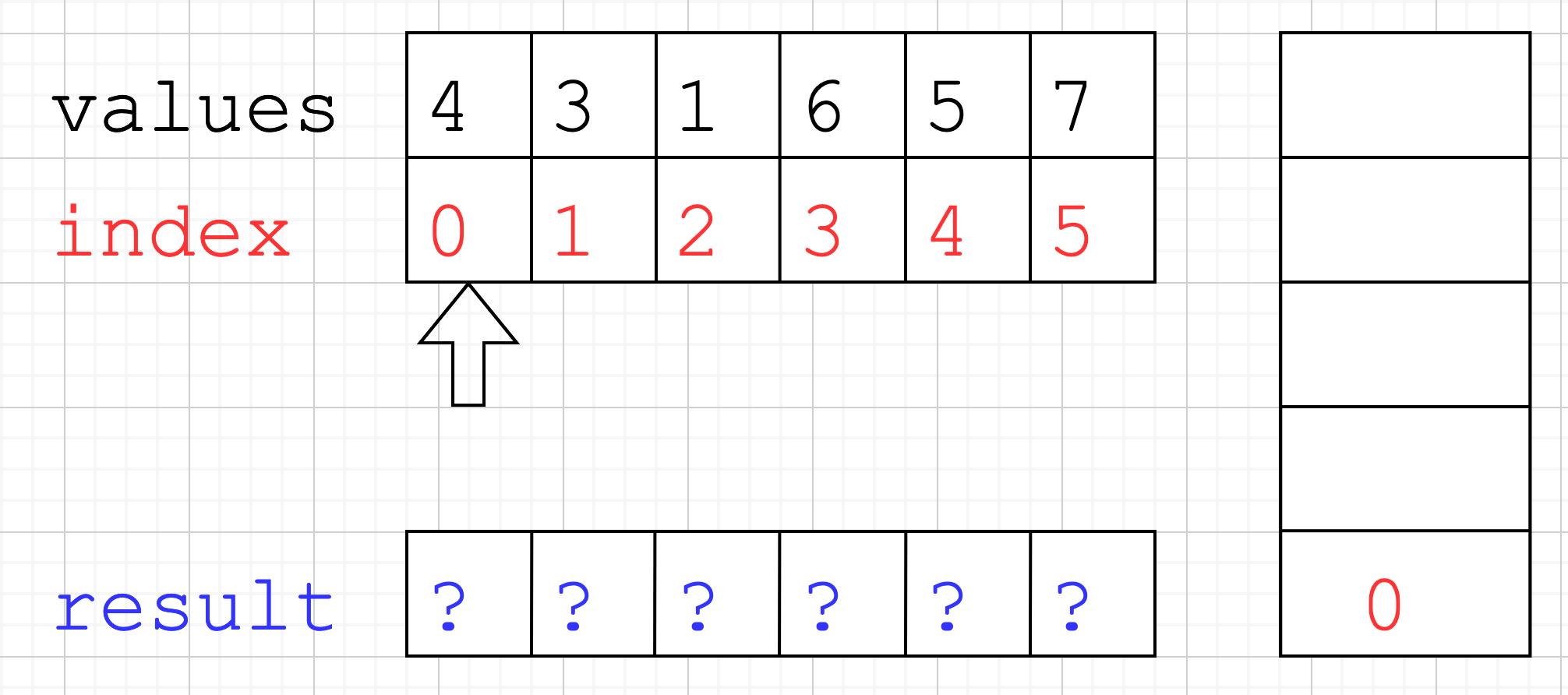
- We process element index
1and value3. As3is smaller than the value referenced by the index at top of the stackvalues[1] < values[0] == 3 < 4, then we don’t do anything and just push index1onto the stack.
- Same as before for index
2.

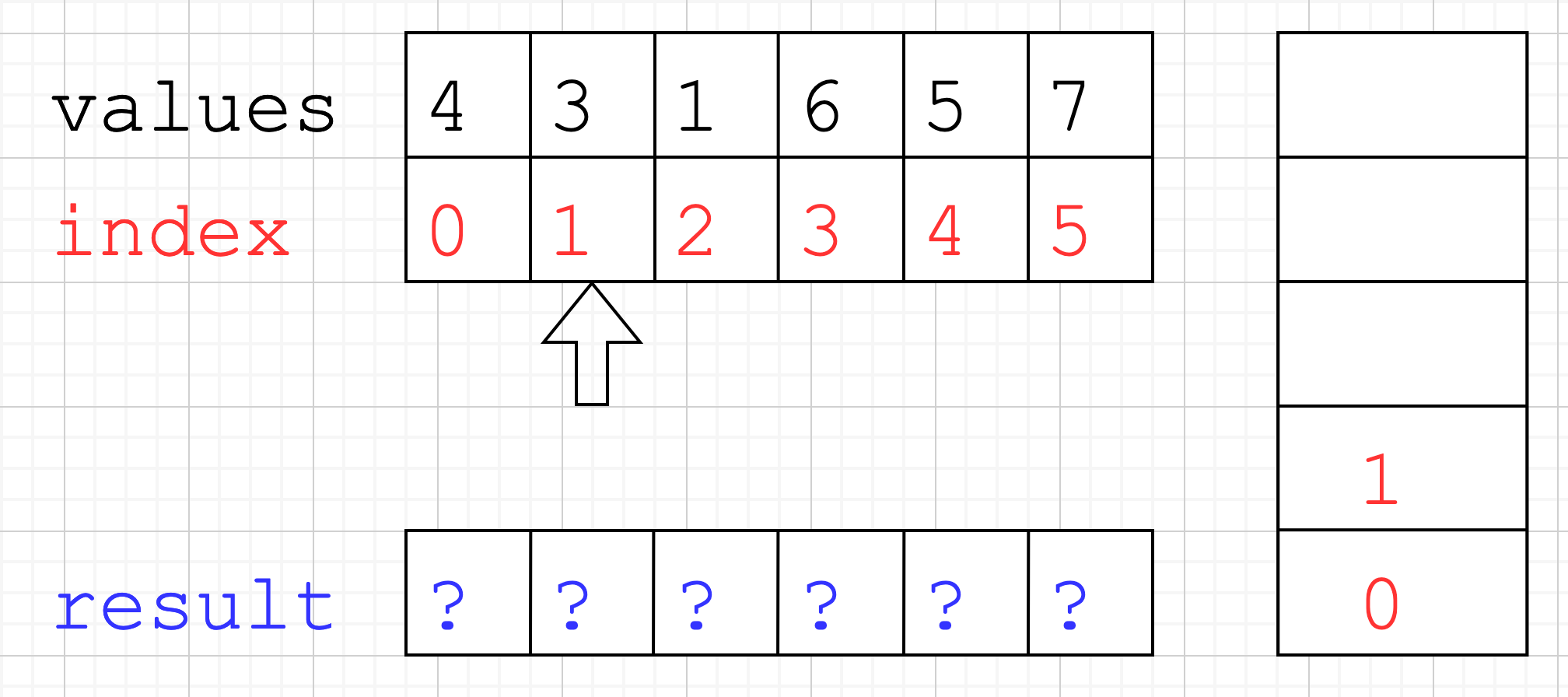
- Here things get interesting. Current index is
3and the value is larger than the one referenced by the top of the stackvalues[3] > values[2] == 6 > 1. - So we pop index
2from the stack, andresult[2] = 3 - 2. - In code this would be
result[topOfStack] = current - topOfStackwheretopOfStack = 2andcurrent = 3.
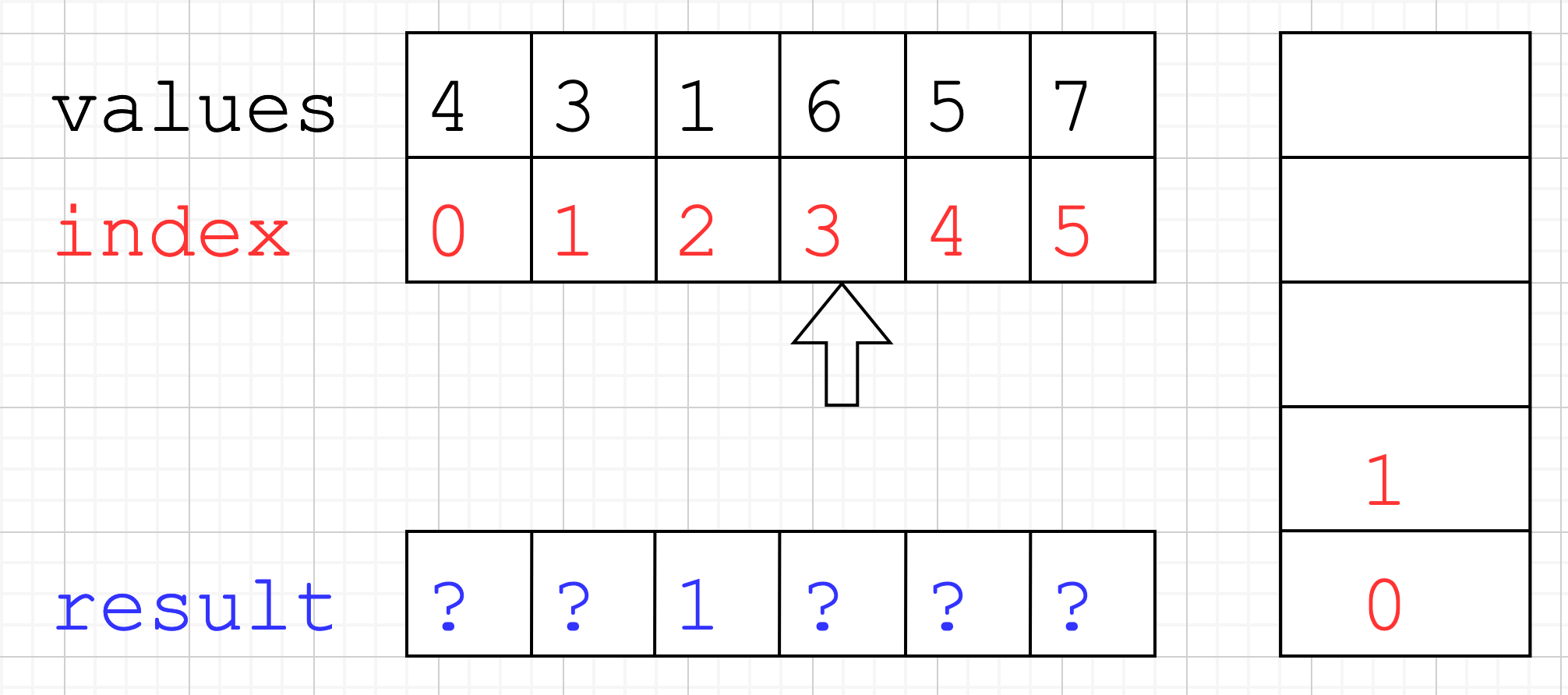
- Current index is still
3but we haven’t finished processing all the possible elements from the stack. - So we pop index
1from the stack, andresult[1] = 3 - 1. - We do the same for index
0andresult[0] = 3 - 0. - Finally we push index
3as we cannot calculateresult[3]yet.
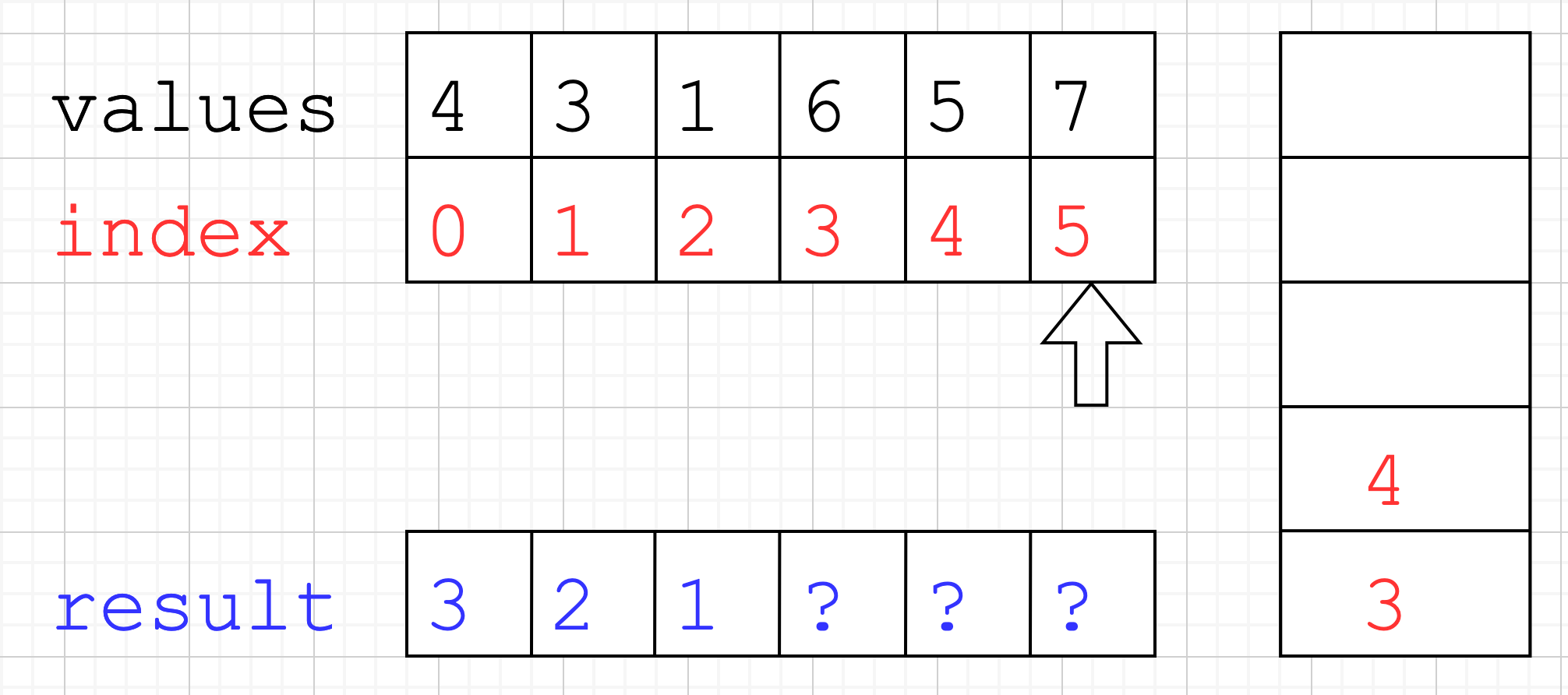
- With the same logic as in the first steps, we push index
4onto the stack.
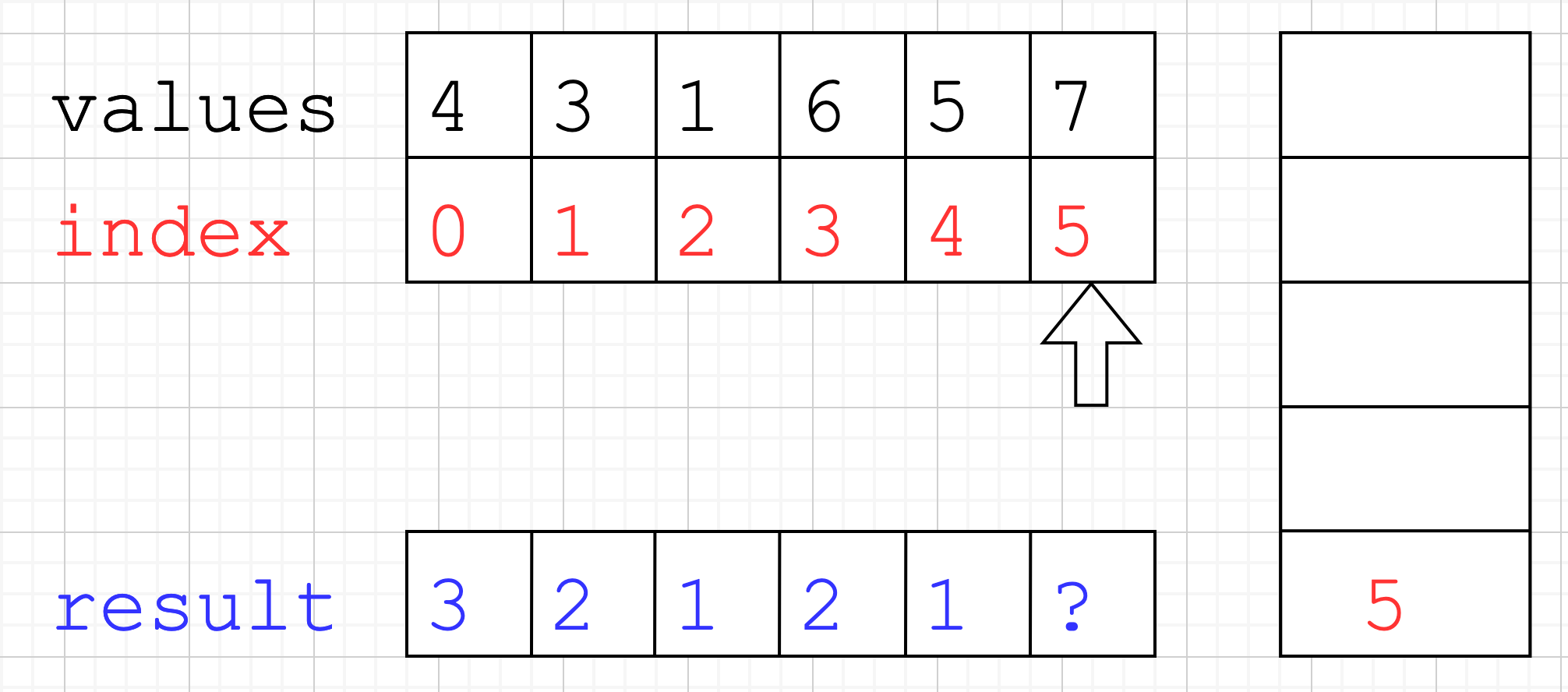
- Current index is
5and the value is larger than the one referenced by the top of the stackvalues[5] > values[4]. - So we pop index
4from the stack, andresult[4] = 5 - 4. - We finish processing the array and there is still an element in the Stack. Remember what I said about Java initialising
arrays with a
0in every position? Due to that we don’t need to do any processing for those elements that are still in the stack.
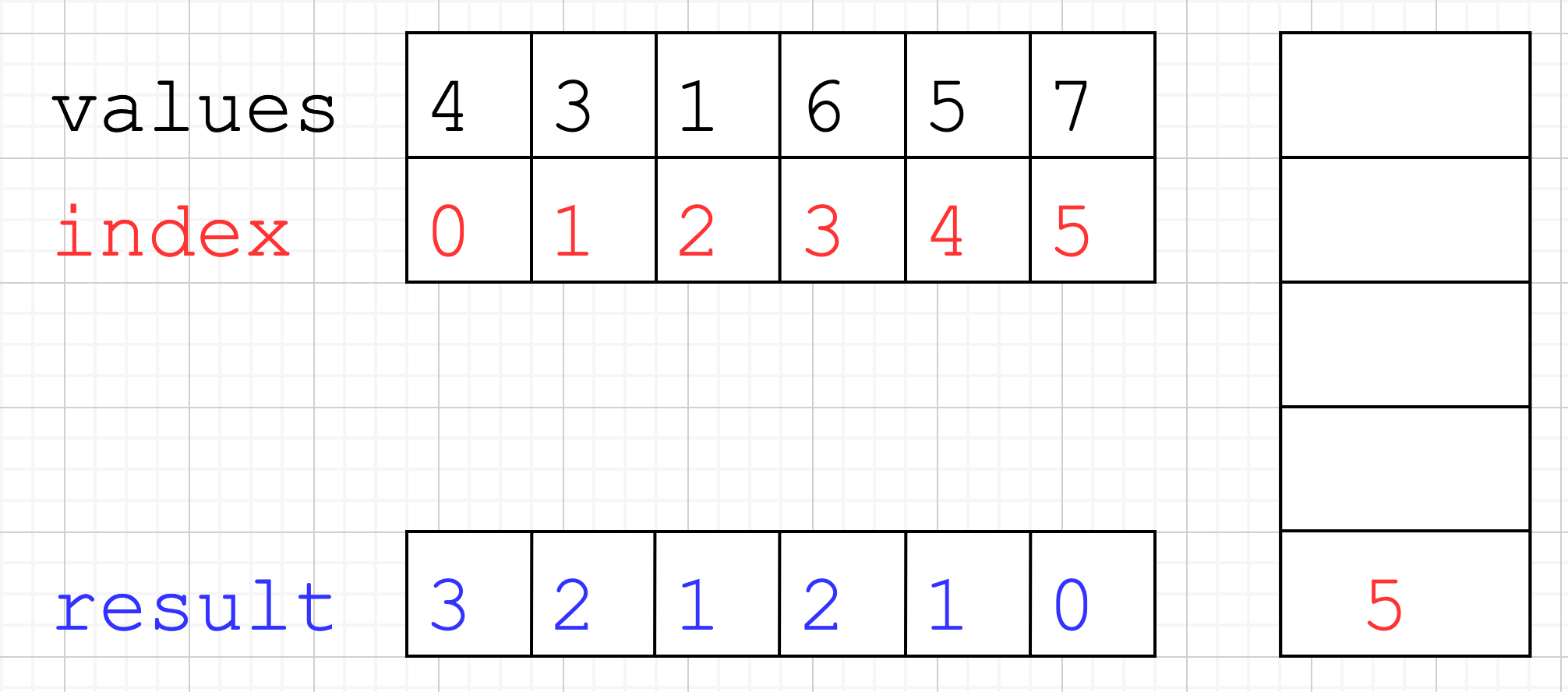
Let’s see how that looks like in code:
public int[] dailyTemperatures(int[] values) {
Stack<Integer> stack = new Stack<>();
int[] result = new int[values.length];
for (int i = 0; i < values.length ; i++) {
while (!stack.isEmpty() && values[stack.peek()] < values[i]) {
int lastIndex = stack.pop();
result[lastIndex] = i - lastIndex;
}
stack.push(i);
}
return result;
}The design flaw of Java Stack
In the previous code I used a Java Stack but the usage of this collection is disencouraged. Why? Java Stack inherits from Vector,
which is a clear violation of the Liskov substition principle. This inheritance allows Stack users to use methods such as stack.add(index, element) which doesn’t make sense for such data structure.
An Stack should only allow users to push/pop elements to/from the top of the stack and that’s it.
Both Stack and Vector were included with the first release of Java, so this flaw in the Stack design is something that has been carried
around for long time. The way Java fixed this flaw, is by introducing a proper Deque<E> interface in version 6.
Stack documentation says:
A more complete and consistent set of LIFO stack operations is provided by the Deque interface and its implementations, which should be used in preference to this class. For example:
Deque<Integer> stack = new ArrayDeque<Integer>();
Conclusion
A monotonic stack is a fancy name for a stack where we store values that are either monotonically increasing or decreasing (depending on our needs). The idea of remembering contiguous sequences so we can use them in the future when processing other elements is both simple and powerful.
This solution runs in linear time O(n) as we only process each element once (think about how many items each element enters into the stack).
Space complexity is also O(n) (don’t even think about the result array), because in the worst case scenario our stack will be full with all
the N elements to be processed. That would happen if the input array contains a monotonically decreasing sequence.
Still want more? Here you have a list of coding challenges that can be solved by using a Monotonic Stack.
Hope you liked the explanation!
Comments